|
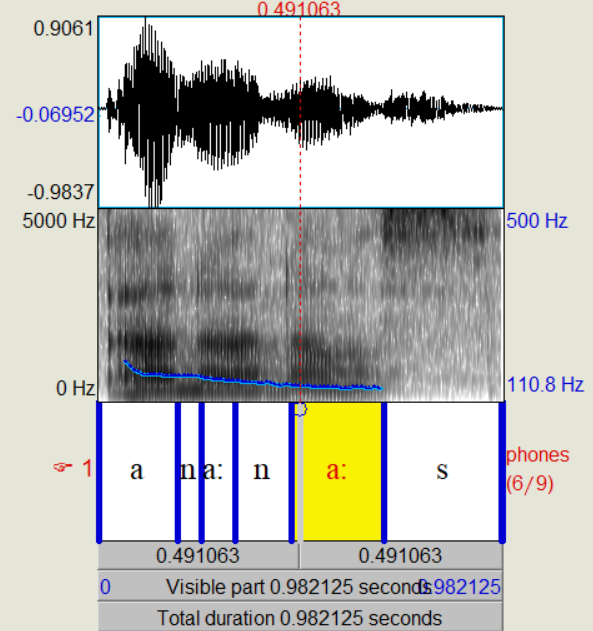
"Eskimo":
|
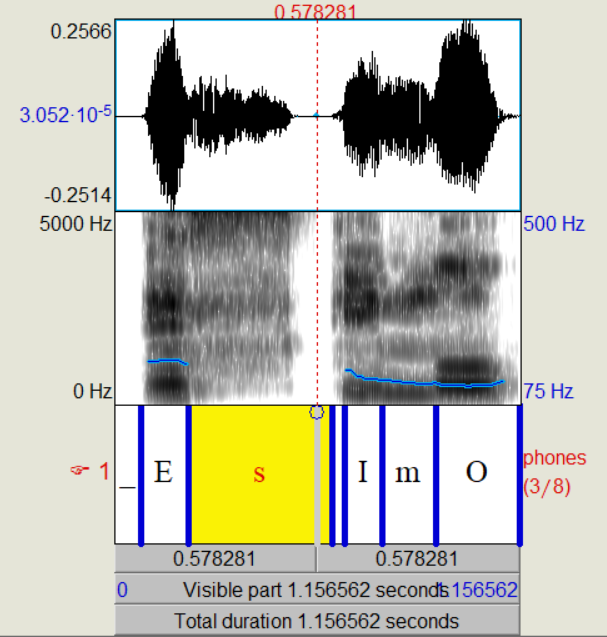
"Salami":
|
Mit dem Headset und PRAAT soll von jedem Gruppenmitglied ein anderes dreisilbiges Wort und außerdem ein kurzer Satz aufgezeichnet werden.
Originale Audio Aufnahme unsere Gruppe mit Braat App:
Jetzt soll die phonetische Transkription erfolgen.
z.B.: Das Wort "Sprachlabor" würde folgendermaßen aussehen:
[SpRa:xlabo:6]
|
|
|
|
|
|
Es sollen nun Transkriptionstabellen der jeweiligen Worte angefertigt werden:
und hier sieht man die in Exceltabelle wie folgendes:

|
Gib das synthetische Wort wieder und vergleiche mit dem Original. Dazu kann das
synthetische in ein WAV-File exportiert werden. Sieh dir das synthetische File in PRAAT an und
kontrolliere ob die Lautlängen und die Grundfrequenz korrekt realisiert wurden
Die gesprochenen Worte und der Satz werden nun mithilfe der Sprachsynthese-Software "mbrola" synthetisiert:
PHO Datei Ananas:
Cick Here
PHO Datei Eskimo:
Click Here
PHO Dateie Salami: Click Here
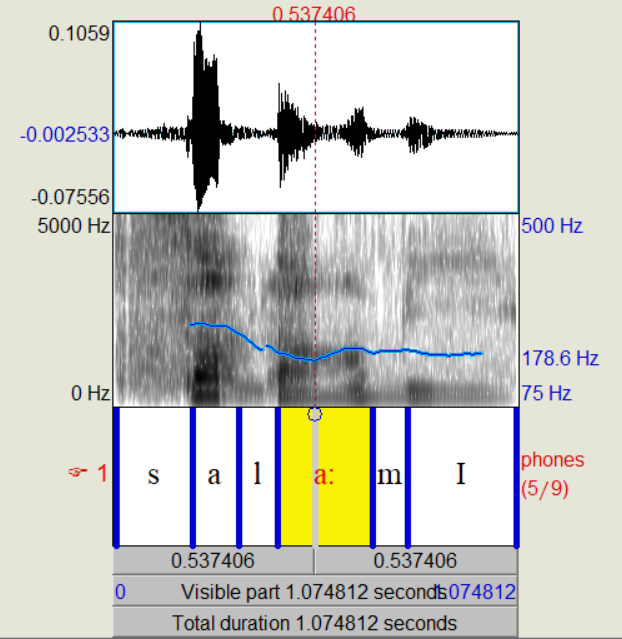
Wie unterscheidet sich die Synthese-Wellenform vom Original??
manche Laengen werden verschluckt wie bei I am ende von Salami
und das haben wir vermeidet durch Dupploung von gleiche reiche: 289 0 201.1 25 198.1 65 192.7
Wie unterscheidet sich die Synthese-Wellenform vom Original?
Das Sprachtempo wird gut nachgebildet, klingt aber bisschen wie Robot. Vor allem an Stellen, an denen wir beim sprechen Laute verschluckt haben,
erwiesen sich als schwieriger bei der Synthese.
Die Stimme von Saba beim synthetisierte stimme klingt besser nach am Original, bei Janod und Evan war aber nicht so
Wie gut werden die Dauern und die Grundfrequenzkontur des Originals nachgebildet?